
2D to 3D localization

3D to 2D localization
2D to 3D localization
3D to 2D localization
Global visual localization in LiDAR-maps, crucial for autonomous driving applications, remains largely unexplored due to the challenging issue of bridging the cross-modal heterogeneity gap. Popular multi-modal learning approach Contrastive Language-Image Pre-Training (CLIP) has popularized contrastive symmetric loss using batch construction technique by applying it to multi-modal domains of text and image.
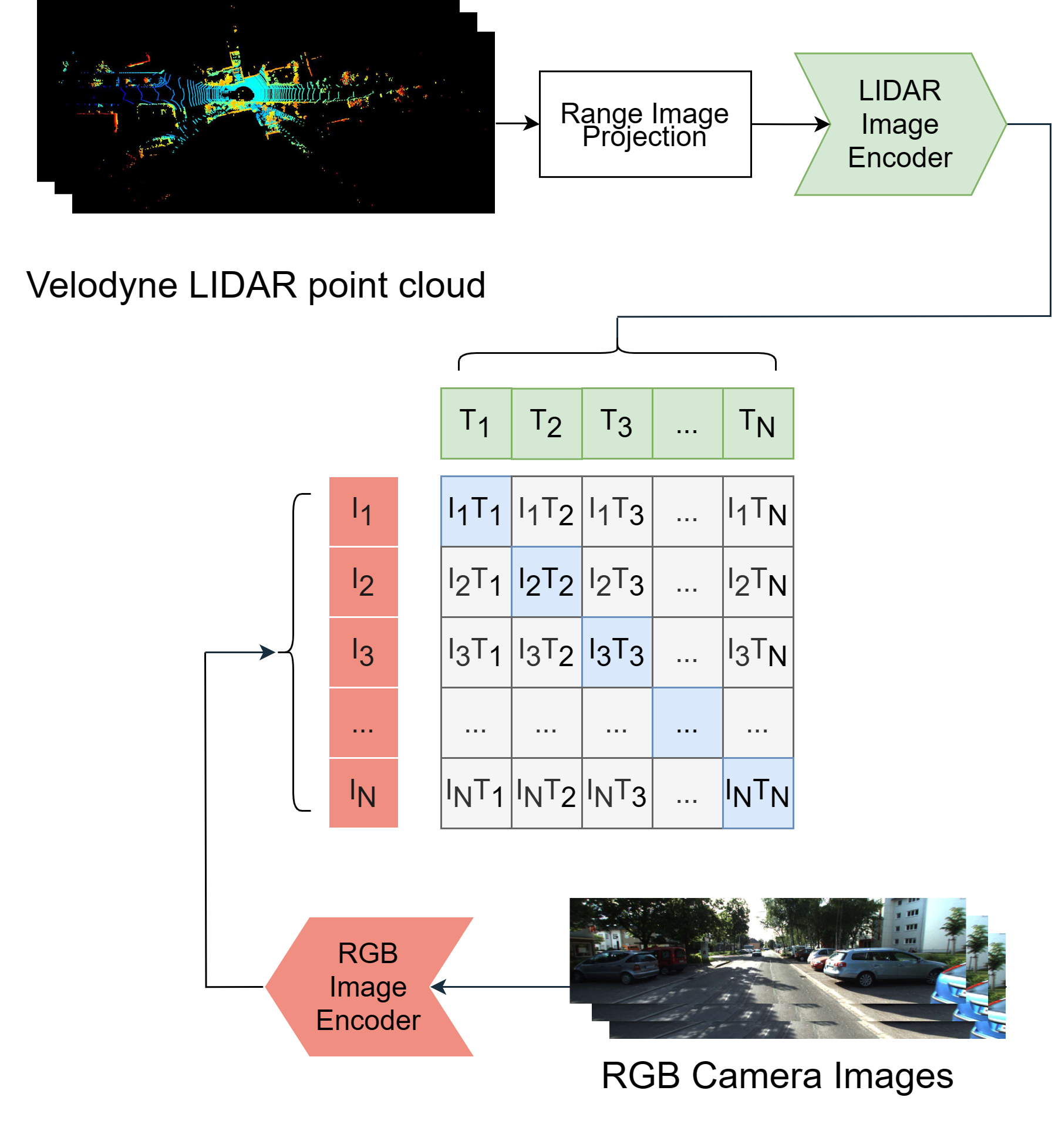
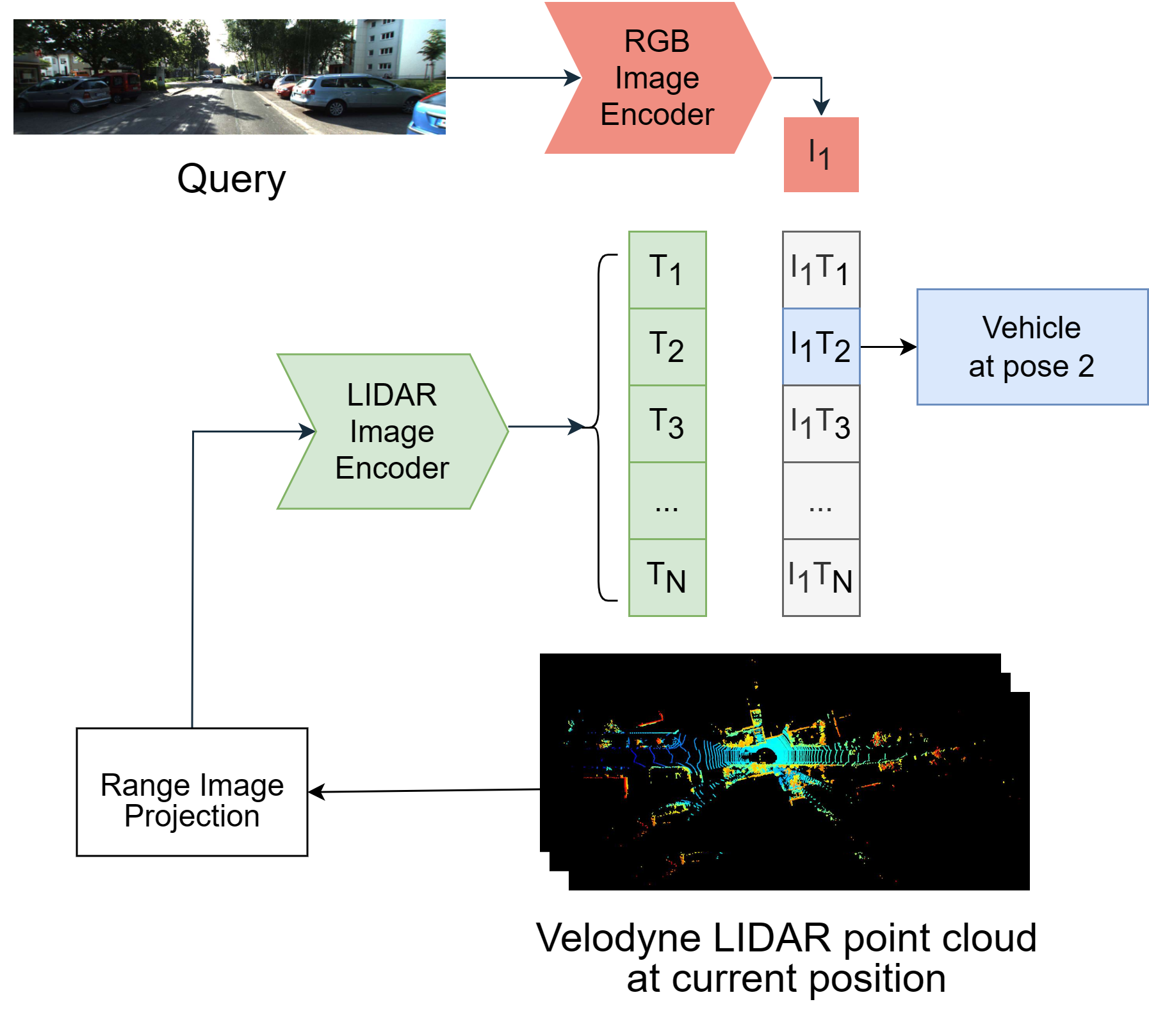
We apply this approach to the domains of 2D image and 3D LiDAR points on the task of cross-modal localization. Our method is explained as follows: A batch of N (image, LiDAR) pairs is constructed so as to predict what is the right match between N X N possible pairings across the batch by jointly training an image encoder and LiDAR encoder to learn a multi-modal embedding space. In this way, the cosine similarity between N positive pairings is maximized, whereas that between the remaining negative pairings is minimized.
Finally, over the obtained similarity scores, a symmetric cross-entropy loss is optimized. To the best of our knowledge, this is the first work to apply batched loss approach to a cross-modal setting of image & LiDAR data and also to show Zero-shot transfer in a visual localization setting. We conduct extensive analyses on standard autonomous driving datasets such as KITTI and KITTI-360 datasets.
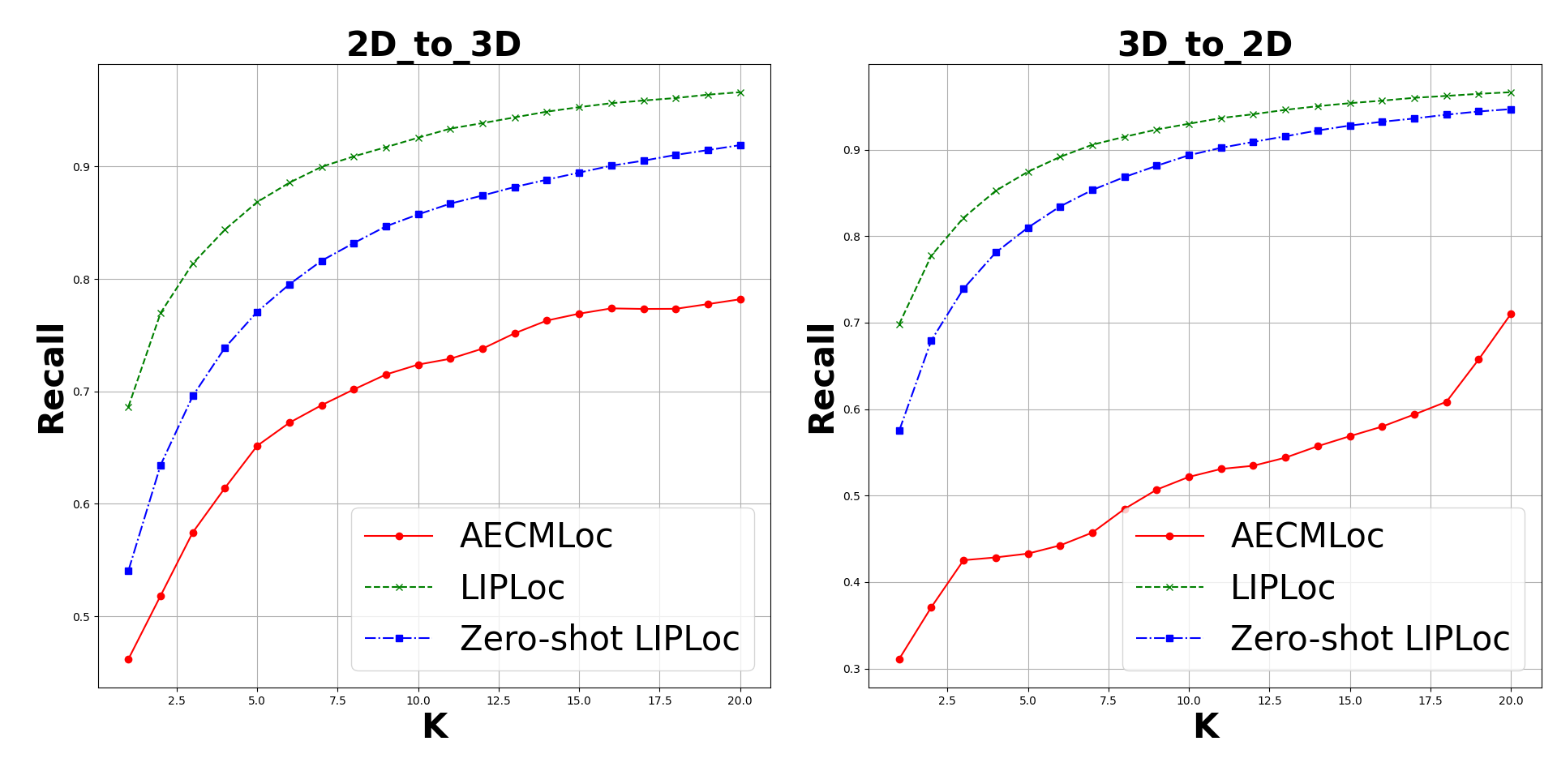
Baseline Comparison with LIPLoc
Our method outperforms state-of-the-art recall@1 accuracy on the KITTI-360 dataset by 22.4%, using only perspective images, in contrast to the state-of-the-art approach, which utilizes the more informative fisheye images. Additionally, this superior performance is achieved without resorting to complex architectures. We also demonstrate the zero-shot capabilities of our model and we beat SOTA by 8% without even training on it. Furthermore, we establish the first benchmark for cross-modal localization on the KITTI dataset.

2D-3D Qualitative Visualization

3D-2D Qualitative Visualization
@InProceedings{Shubodh_2024_WACV,
author = {Shubodh, Sai and Omama, Mohammad and Zaidi, Husain and Parihar, Udit Singh and Krishna, Madhava},
title = {LIP-Loc: LiDAR Image Pretraining for Cross-Modal Localization},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops},
month = {January},
year = {2024},
pages = {948-957}
}